Exareme
Sailing through Flows of Big Data
Exareme Architecture
The system architecture is shown in Figure 2. From a user’s point of view, the system is used as a traditional database system: create / drop tables or indexes, import external data, issue queries, and more. Queries read the input from several tables that are partitioned and process them, possibly in parallel. The queries are expressed in ExaDFL and are transformed into data processing flows (dataflows) represented as directed acyclic graphs (DAGs) that have arbitrary computations as nodes and producer- consumer interactions as edges. The typical queries we target are complex data-intensive transformations that are expensive to execute: queries may run for several minutes or hours.
EXAREME is built on top of IaaS clouds using the compute and storage services typically offered by providers. At the IaaS level, clouds offer compute resources in the form of VMs. The cost of leasing a VM is based on a per time-quantum pricing scheme (typically 1 hour) and is pre-paid, i.e., one pays for the entire quantum independently of the extent of the use of resources. One important design decision of EXAREME is to separate processing from storage. The tables are partitioned and stored to the storage service and each worker fetches the partitions needed and caches them to its local disk for subsequent usage. The optimizer takes into account partition placement to benefit from data locality. We do this for two reasons: flexibility and cost. This scheme is very flexible because decoupling compute from storage resources is crucial for the elasticity of the system; VMs can be added and removed easily. Furthermore, storing the data in the compute cloud is very expensive. With current Amazon rates, storing 1 TB of data for 1 month in S3 will cost approximately $10 and keeping it cached in EC2 without replication will cost approximately $2580, which is more than two orders of magnitude more expensive.
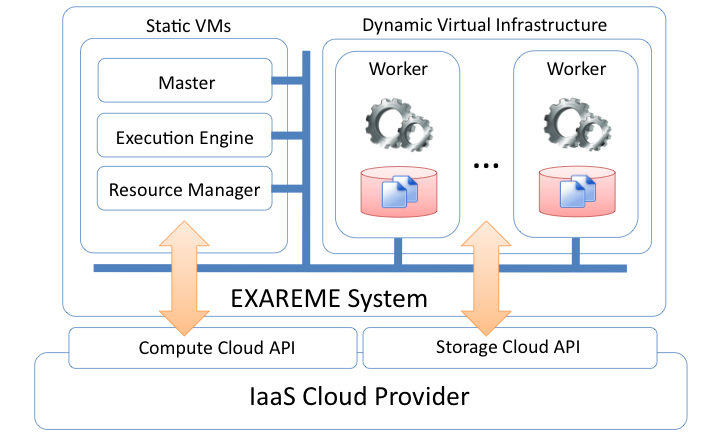
EXAREME is separated into the following components: The Master is the main entry point and is responsible for the co- ordination of the other components. All the information related to data and allocated VMs is stored in the Registry. The Resource Manager allocates and deallocates VMs based on the demand. The Optimization engine translates the ExaQL (or ExaDFL) query into the distributed machine code of the system taking into account the monetary cost. The Execution Engine communicates with the resource manager to reserve the resources needed for the execution and starts scheduling the operators of the query respecting their dependencies in the dataflow graph and the available resources. It is also responsible for the re-execution of failed operators and the release of resources. Finally, the Worker executes operators (relational and UDFs) and transfers intermediate results to other workers.
Following a top to bottom description of the main components:
Optimization Engine
The goal of the optimizer is to transform exaDFL into the low-level distributed machine code of the system. The latter is used to express dependencies between the operators of the dataflow graph in the form of a directed acyclic graph (DAG) and is similar to the DAGMan language. In a cloud environment, the monetary cost of using the resources is as important as the completion time of the dataflows. The optimizer of Exareme finds a skyline of solutions, each with a different tradeoff between the completion time and the monetary cost.
Resource Mediator
The execution engine communicates with the resource mediator to allocate the resources needed for the execution of the particular dataflow. It also provides to the resource mediator the output of the optimizer that essentially is a timeline with containers and operators. We call the usage of containers over time a query pattern (we do not care about the operators at this level). Given all the patterns of the currently active queries, the mediator assigns query containers to machines.
In a cluster environment, the total number of machines is fixed. In this setting, the resource mediator tries to do load balancing of query containers to machines. In a cloud environment however, the number of machines is not fixed. In this setting, the virtual cluster size is automatically adjusted based on container demand. The mediator takes into account the monetary cost of leasing a new container, and it does so only when the demand is appropriate.
Execution Engine
The execution engine is responsible for the coordination and monitoring of the dafaflows. We have designed and developed from scratch an asynchronous event-based engine. The input to the engine is the low-level distributed machine code. The engine monitors the execution and handle failures by materializing intermediate results and recover from failure by restarting operators, possibly to different containers. All the components of the system (the optimizer, the containers, and the execution engine itself) create events that are processed by the engine. The execution engine retrieves the independent events from the queue and evaluate them in parallel using a thread pool. An example is the Instantiate Operator event. This event instantiates an operator to a particular container. Independent events are typically events that involve different containers, e.g., instantiate two operators to different containers.
Worker Container
The container is the abstraction of the resources of physical or virtual machines and is responsible for the storage of table partitions, the execution of ExaQL queries, and the transferring of the intermediate results. It is well understood that the performance of the individual nodes affects the whole performance of the distributed system. We have payed special attention to implement an efficient query engine with native UDF support.
We have implemented the container on top of the SQLite database using the APSW Python wrapper. Exareme process the data in a streaming fashion, performing pipelining when possible, even for the UDFs. Furthermore, it does in-database processing in order to push the UDFs as close to the data as possible. The UDFs are executed inside the database along with the relational operators. This makes possible to process large amount of data. Finally, the execution of the queries has ACID guarantees as long as the UDFs are side-effect free, which is the usual case.
The code of the container is open-source and available online with the MIT licence. The available code runs on a single machine with minimal installation requirements (Python and APSW) and provide all the available functionality of the system.