Exareme
Sailing through Flows of Big Data
About Exareme
The name is inspired, on the one hand, by hexareme, an ancient Greek type of warship with six rows of oars moving in a coordinated fashion to obtain great speed and agility, and on the other hand, by the long-term goal of exascale data processing.
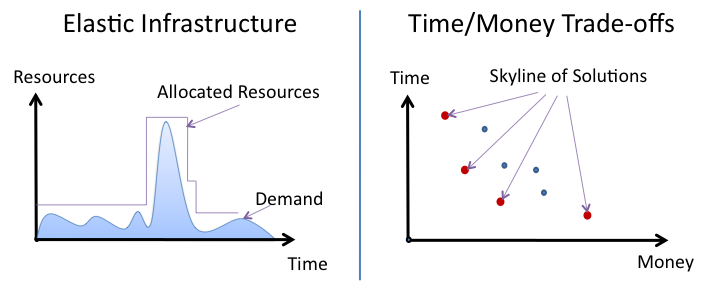
Modern applications face the need to process large amount of data using complex functions. Such rich tasks are typically expressed using high-level APIs or languages and are transformed into data intensive workflows, or simply, dataflows. Infrastructure-as-a-Service (IaaS) clouds have become attractive platforms for large-scale dataflow processing. IaaS cloud providers typically offer virtual machines (VMs) and storage as services. The defining characteristic of IaaS clouds is elasticity, i.e., they offer the ability to create dynamic virtual infrastructures that can change in size by allocating and deallocating compute and/or storage resources. This elasticity property of clouds is illustrated in the left part of Figure 1. The system reserves resources to meet the dataflow demand and releases them when the demand is reduced. In addition, there is another kind of elasticity present in clouds, which captures the trade-offs between the response time of the system on a query and the amount of money we pay for it. To distinguish it from the traditional notion, in this paper, we refer to it as eco-elasticity. This notion comes from economics and is illustrated in the right part of Figure 1. The figure shows different ways of executing a particular query, with each solution being a point in the 2D space corresponding to a different trade-off between time and money. The optimal trade-offs are the ones that belong to the skyline.
In clouds, both elasticity and eco-elasticity are very important. The monetary cost of using the resources is directly related to the energy spend on the cloud provider’s side. It has been argued that to fully exploit IaaS cloud potential, elasticity has to be deeply embedded into the core of data processing systems. Current data management techniques proposed for the cloud focus on performance. To take advantage of elasticity, these techniques and systems have to be revisited. However, to account for elasticity, many critical components of data processing systems must be revisited and changed, including the storage manager, the optimization algorithms, and the execution engine. Thus, it is extremely difficult to change existing systems since their goal is performance. All the above call for a new system.
We introduce EXAREME, a system for elastic large-scale dataflow processing on the cloud. With EXAREME, our goal has been to develop an efficient system that fits closely to the computational model of clouds by i) exploiting both elasticity and eco-elasticity properties of IaaS clouds, ii) defining language abstractions that can declaratively express data parallelism and complex computations using user-defined-functions (UDFs), iii) providing efficient execution of UDFs using Just-In-Time (JIT) tracing compilation techniques. To the best of our knowledge, EXAREME is the first effort to build a system that exploits both elasticity properties in IaaS clouds.
The contributions of exareme are summarized as follows:
Elasticity: EXAREME exploits both elasticities of clouds and critical system components are especially designed for that. The system changes dynamically the size of the allocated virtual infrastructure and it deals with the concept of multi-dimensional optimization offering trade-offs between time and money. A major challenge is the data partitioning scheme in order to avoid significant network traffic.
Declarative Languages: The system offers two languages at different levels of abstraction. The high-level language (ExaQL) is based on SQL enhanced with a syntax that makes it easy to write data pipelines. The dataflow language (ExaDFL) offers a set of primitives to declare data parallelism, which enables the system to scale automatically and choose the appropriate degree of parallelism in each case.
Native UDF execution: The system natively supports UDFs with arbitrary user code. The engine blends the execution of UDFs together with relational operators using JIT tracing compilation techniques. This greatly speeds-up the execution as it reduces context switches, and most importantly, only the relevant execution traces are used, allowing the engine to perform optimizations at runtime that are not possible when the query is pre-compiled.
In addition to the above, the system has the following features:
- EXAREME supports complex data types and UDFs with arbitrary user code, which are very important for modern cloud applications.
- The system architecture is separated into components with well-defined semantics which makes it easy to change implementations. flexible since the implementations of different components can change with- out affecting the entire system.
- Compression techniques are important for large amounts of data. For network data transferring, we use a hybrid approach based on state-of- the-art column-row store formats.
- Finally, EXAREME is ideal for rapid experimentation and data exploration. It allows access to external sources without the need to explicitly import them and provides a rich set of UDFs for data manipulation.
This technical report present a comparison of exareme against cloudera’s impala.